
In today’s data-driven world, businesses are constantly looking for ways to streamline their data management processes and maximize the value of their data assets. One approach that has gained popularity in recent years is virtualization, which allows multiple virtual resources to run on a single physical resource.
Virtualization has many benefits, including increased efficiency, scalability, and cost savings.
Two types of virtualization that are commonly used in data management are data virtualization and database virtualization. While these terms are sometimes used interchangeably, they actually refer to two different concepts with distinct goals and processes. In this post, we will explore the difference between data virtualization and database virtualization, and provide guidance on how to choose the right approach for your business.
Whether you are a data architect, a business analyst, or an IT manager, understanding the difference between these two types of virtualization is essential for making informed decisions about your data management strategy.
What is Database Virtualization?
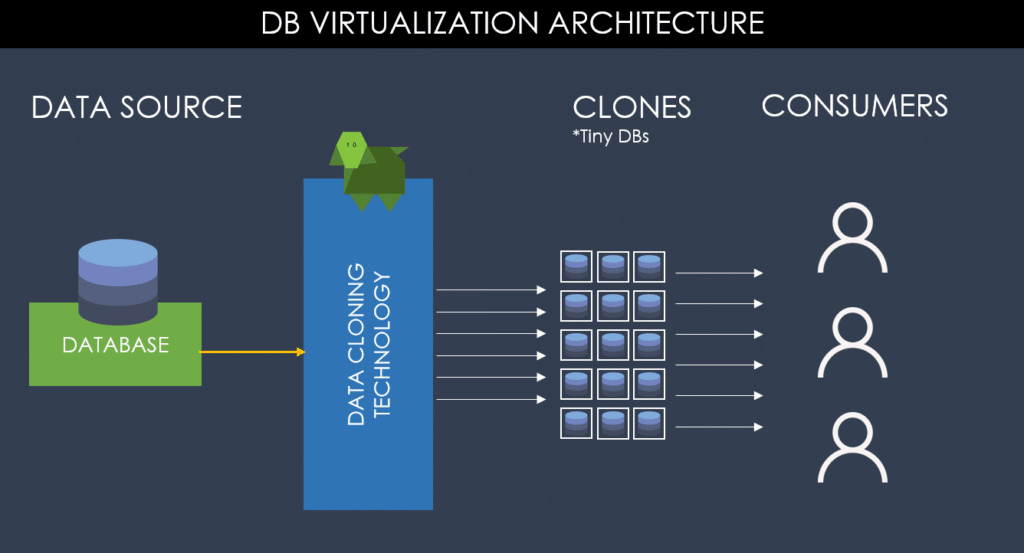
Database virtualization is the process of creating multiple virtual databases that run on a single physical database. Each virtual database appears to the users and applications as a separate database, with its own schema, tables, and data.

However, all the virtual databases share the same underlying physical resources, such as disk space, memory, and CPU.
Database virtualization is often referred to as “data cloning” because it allows organizations to create copies of their databases quickly and easily, without having to physically move or duplicate data. This is particularly useful in environments where multiple copies of the same database are needed for development, testing, or reporting purposes.
Database virtualization has several advantages over traditional database management approaches.
- First, it reduces hardware costs by allowing multiple databases to share the same physical resources.
- Second, it improves data isolation and security, as each virtual database can have its own access controls and security policies.
- Third, it simplifies database management, as administrators can manage multiple virtual databases from a single console.
Database virtualization is compatible with various database management systems, including Oracle, SQL Server, and MySQL, and can be deployed on-premises or in the cloud. It is a powerful tool for organizations that need to manage large volumes of data while maintaining flexibility and scalability.
What is Data Virtualization?
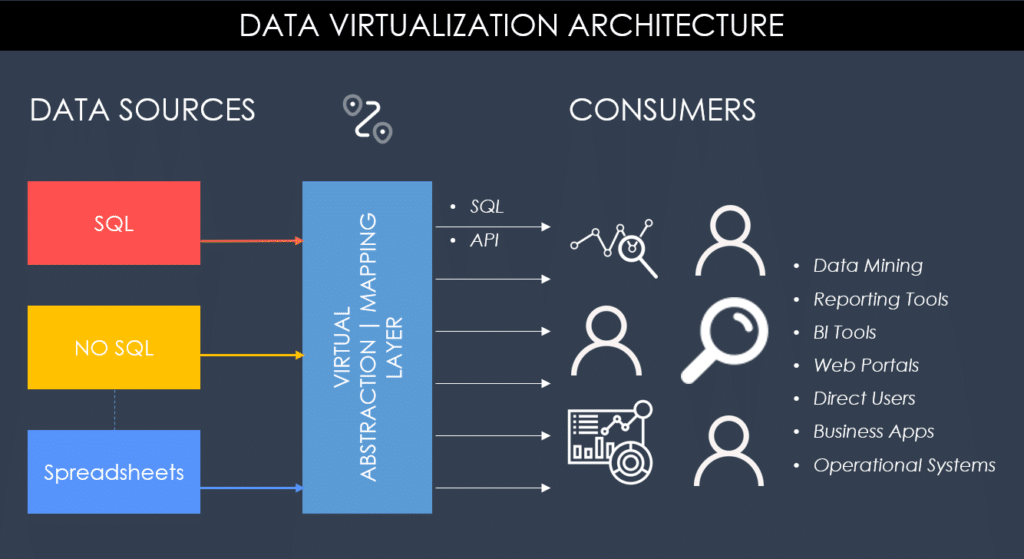
Data virtualization is the process of abstracting data from various sources, such as databases, data warehouses, and cloud services, and presenting it as a single, unified view.
With data virtualization, users and applications can access and analyze data in real-time, without having to physically move or copy data from one place to another.
Data virtualization is often used in environments where data is dispersed across multiple sources, or where data integration is a complex and time-consuming process. By creating a virtual layer on top of the data sources, data virtualization allows organizations to access and manipulate data as if it were stored in a single location.
Data virtualization has several advantages over traditional data integration approaches.
- First, it reduces data redundancy and improves data quality, as users and applications access a single version of the data.
- Second, it increases agility and flexibility, as changes to the underlying data sources can be reflected in the virtual layer without requiring modifications to the applications.
- Third, it simplifies data management, as administrators can manage data sources and access controls from a single console.
Data virtualization is compatible with various data sources and formats, including structured and unstructured data, and can be deployed on-premises or in the cloud. It is a powerful tool for organizations that need to integrate data from multiple sources while maintaining real-time access and flexibility.
The Key Differences Between Database Virtualization and Data Virtualization
Although database virtualization and data virtualization share some similarities in terms of their virtualization approach, they are two distinct concepts with different goals and processes.
Database virtualization focuses on creating multiple virtual databases that run on a single physical database. It is primarily used to consolidate database infrastructure, reduce hardware costs, and improve data isolation and security. Database virtualization is commonly used in environments where multiple copies of the same database are needed for development, testing, or reporting purposes.
On the other hand, data virtualization focuses on abstracting data from various sources and presenting it as a single, unified view.
It is primarily used to integrate data from multiple sources, improve data quality, and increase agility and flexibility. Data virtualization is commonly used in environments where data is dispersed across multiple sources, or where data integration is a complex and time-consuming process.
Another key difference between database virtualization and data virtualization is their level of abstraction. Database virtualization creates virtual databases that are isolated from each other and from the physical database. In contrast, data virtualization creates a virtual layer on top of the data sources, allowing users and applications to access the data as if it were stored in a single location.

Which One Should You Choose?
The decision of whether to choose database virtualization or data virtualization depends on several factors, including data architecture, use cases, and IT resources.
If your organization needs to manage multiple copies of the same database for development, testing, or reporting purposes, or if you need to improve data isolation and security, then database virtualization may be the best choice for you.
On the other hand, if your organization needs to integrate data from multiple sources, improve data quality, or increase agility and flexibility, then data virtualization may be the best choice for you.
It’s also important to consider your IT resources when making this decision. Database virtualization typically requires specialized software and hardware, and may require significant upfront investment in infrastructure. Data virtualization, on the other hand, can be deployed on top of existing data sources and may require less upfront investment.
Ultimately, the choice between database virtualization and data virtualization depends on your organization’s specific needs and goals. It’s important to carefully evaluate both approaches and determine which one is the best fit for your data management strategy.
Conclusion
In conclusion, understanding the difference between database virtualization and data virtualization is essential for making informed decisions about your data management strategy. Database virtualization focuses on consolidating databases, while data virtualization focuses on integrating data. While these two concepts share some similarities, they have different goals and processes.
Choosing between database virtualization and data virtualization depends on several factors, including data architecture, use cases, and IT resources.
Organizations that need to manage multiple copies of the same database for development, testing, or reporting purposes may find database virtualization to be the best choice. In contrast, organizations that need to integrate data from multiple sources, improve data quality, or increase agility and flexibility may find data virtualization to be the best choice.
Regardless of which approach you choose, virtualization is a powerful tool for streamlining data management, improving data quality, and reducing costs. Whether you are a data architect, a business analyst, or an IT manager, understanding the difference between database virtualization and data virtualization is essential for making the most of your data assets.
Andrew Walker is a software architect with 10+ years of experience. Andrew is passionate about his craft, and he loves using his skills to design enterprise solutions for Enov8, in the areas of IT Environments, Release & Data Management.
