
In today’s technology-driven world, IT operations play a critical role in the success of businesses and organizations. One key aspect of IT operations is ensuring that systems and applications are reliable and available when needed.
This is where failure metrics come into play. Failure metrics are used to measure the performance and reliability of IT systems, and they help IT teams identify areas that need improvement.
In this article, we will explore three common failure metrics used in IT operations: Mean Time to Repair (MTTR), Mean Time Between Failures (MTBF), and Mean Time to Failure (MTTF). We will explain what each metric measures and when it is most useful.
Additionally, we will discuss the limitations of each metric and why it is important to use all three together to gain a comprehensive understanding of system reliability and performance.
By the end of this article, you will have a better understanding of how to choose the right failure metrics for your IT operations.
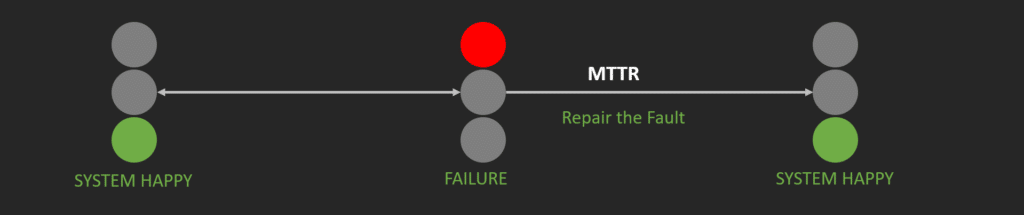
Mean Time to Repair (MTTR)
MTTR is a failure metric that measures the average time it takes to repair a system or application after it fails. MTTR is often used in incident management, where the focus is on restoring service as quickly as possible after an incident occurs.
MTTR is calculated by dividing the total downtime by the number of incidents. For example, if a system experiences 2 hours of downtime due to 4 incidents, the MTTR would be 30 minutes (2 hours divided by 4 incidents).
MTTR is most useful in situations where the primary goal is to minimize the impact of incidents on users or customers. By measuring how quickly IT teams can restore service, organizations can set realistic expectations for downtime and work to improve incident response times.
However, MTTR has limitations as a failure metric. It does not take into account the frequency or severity of incidents, and it does not provide insight into the underlying causes of failures.
As a result, MTTR should be used in conjunction with other failure metrics, such as MTBF and MTTF, to gain a more comprehensive understanding of system reliability and performance.
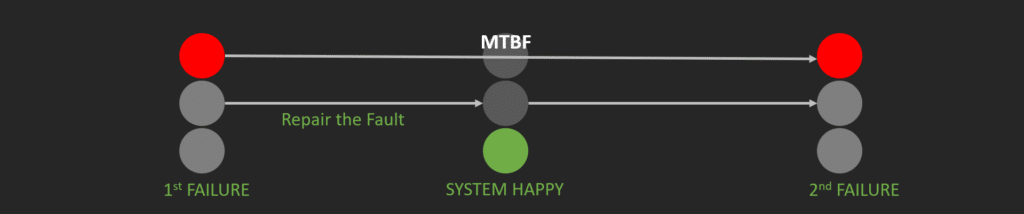
Mean Time Between Failures (MTBF)
MTBF is a failure metric that measures the average time between system or application failures. MTBF is often used to predict when failures are likely to occur and to plan maintenance activities accordingly.
MTBF is calculated by dividing the total uptime by the number of failures. For example, if a system has 100 hours of uptime and experiences 2 failures, the MTBF would be 50 hours (100 hours divided by 2 failures).
MTBF is most useful in situations where the primary goal is to prevent failures from occurring. By understanding how often failures occur and how long systems can operate between failures, IT teams can plan proactive maintenance activities and make changes to improve system reliability.
However, MTBF has limitations as a failure metric. It assumes that failures follow a predictable pattern and that all failures are equal in severity. Additionally, MTBF does not provide insight into how long it takes to repair systems after they fail.
As a result, MTBF should be used in conjunction with other failure metrics, such as MTTR and MTTF, to gain a more comprehensive understanding of system reliability and performance.

Mean Time to Failure (MTTF)
MTTF is a failure metric that measures the average time until a system or application fails. MTTF is often used to predict how long systems can operate before they are likely to fail.
MTTF is calculated by dividing the total operating time by the number of failures. For example, if a system operates for 1000 hours before it fails, and there were two failures during that time, the MTTF would be 500 hours (1000 hours divided by 2 failures).
MTTF is most useful in situations where the primary goal is to predict when failures are likely to occur and to plan maintenance activities accordingly.
By understanding how long systems can operate before they are likely to fail, IT teams can plan proactive maintenance activities and make changes to improve system reliability.
However, MTTF has limitations as a failure metric. It does not take into account the severity of failures, and it assumes that failures follow a predictable pattern. Additionally, MTTF does not provide insight into how long it takes to repair systems after they fail.
As a result, MTTF should be used in conjunction with other failure metrics, such as MTTR and MTBF, to gain a more comprehensive understanding of system reliability and performance.
Choosing the Right Failure Metrics
While each of the three failure metrics discussed above has its own strengths and weaknesses, using all three together can provide a more comprehensive understanding of system reliability and performance.
MTTR is most useful for incident management, where the focus is on restoring service as quickly as possible after an incident occurs.
MTBF is most useful for predicting when failures are likely to occur and planning proactive maintenance activities. MTTF is most useful for predicting how long systems can operate before they are likely to fail.
By using all three metrics together, IT teams can gain a more complete picture of system reliability and performance.
For example, if MTTR is high and MTBF is low, it may indicate that incidents are being resolved quickly, but systems are failing frequently. Alternatively, if MTBF is high and MTTF is low, it may indicate that systems are reliable between failures, but are failing earlier than expected.
In addition to using all three metrics together, it’s important to consider the specific needs and goals of your organization when choosing failure metrics.
For example, if your organization is focused on minimizing downtime and improving incident response times, MTTR may be the most important metric to track.
Alternatively, if your organization is focused on maximizing system uptime and reducing maintenance costs, MTBF and MTTF may be more relevant metrics to track.
Ultimately, the key to choosing the right failure metrics is to understand the strengths and limitations of each metric and to use them in a way that provides the most useful insights for your organization.

Conclusion
Choosing the right failure metrics is critical for ensuring that IT systems and applications are efficient, reliable, and available when needed.
While Mean Time to Repair (MTTR), Mean Time Between Failures (MTBF), and Mean Time to Failure (MTTF) are all useful metrics for measuring system reliability and performance, each metric has its own strengths and weaknesses.
MTTR is most useful for incident management, MTBF is most useful for predicting when failures are likely to occur, and MTTF is most useful for predicting how long systems can operate before they are likely to fail.
However, using all three metrics together can provide a more comprehensive understanding of system reliability and performance.
When choosing failure metrics, it’s important to consider the specific needs and goals of your organization.
By understanding the strengths and limitations of each metric and using them in a way that provides the most useful insights for your organization, you can make more informed decisions about maintenance activities, system upgrades, and other IT initiatives.
In summary, by using the right failure metrics, IT teams can ensure that systems and applications are reliable, available, and meet the needs of the organization.
Other Reading
Interested in reading more about Test Environment Management. Why not start here:
Enov8 Blog: Top 5 Cloud Metrics
Enov8 Blog: Top 5 Container Metrics
Medium: Importance of TEM Metrics

Author Andrew Walker
Andrew Walker is a software architect with 10+ years of experience. Andrew is passionate about his craft, and he loves using his skills to design enterprise solutions for Enov8, in the areas of IT Environments, Release & Data Management.